O Fim da Transição: A Estrutura de Design e Desenvolvimento de Produtos para 2026
Durante décadas, construir um produto era uma corrida de revezamento — da pesquisa ao design, da programação ao controle de qualidade — e o bastão era perdido em cada etapa. Em 2026, essas etapas desaparecerão.

Todo desenvolvedor já viveu esta cena: o designer entrega o arquivo do Figma, o dev abre no editor e algo se perde na tradução. O espaçamento que era 16px vira 17px. A cor que era quase aquela vira outra. O componente que parecia simples esconde três estados que ninguém documentou. O problema nunca foi competência — foi a passagem de bastão.
Por décadas, construir um produto foi um revezamento: pesquisa entrega para design, design entrega para código, código entrega para o QA. A cada passagem, informação vazava e tempo evaporava. A linha de montagem era previsível e lenta, e o bastão caía em toda troca de mãos.
Em 2026, as passagens estão sumindo. Três forças estão dissolvendo a fronteira entre desenhar e construir um produto: uma IA que valida a ideia antes de você escrever a primeira linha, tokens em JSON que fazem design e código lerem da mesma fonte, e o open code, que devolve ao desenvolvedor — e à IA — a posse dos componentes. A linha virou um loop.
Este é o stack que substituiu o revezamento — e, no fim, ele muda menos a sua ferramenta e mais o seu trabalho.
A linha de montagem acabou
O modelo antigo era uma reta: Pesquisa → Design → Código → QA. Cada etapa terminava num documento que a próxima precisava reinterpretar — o relatório de pesquisa, o arquivo de design, a biblioteca de componentes. E reinterpretar é onde os bugs e os mal-entendidos moram.
O modelo de 2026 não é uma reta; é um ecossistema interligado, um loop onde a IA faz a ponte entre a suposição e o dado, e o JSON conecta o design ao código. As quatro forças a seguir são o que fecha esse circuito — e vale olhar uma a uma, porque cada uma sela uma das passagens que vazavam.
Pesquisa sintética: pressionar a ideia antes de construí-la
A primeira passagem que vazava ficava logo no começo: validar uma ideia com usuários reais é lento e caro, e quando você enfim consegue acesso, já investiu semanas. A pesquisa sintética inverte isso. Você gera personas com um LLM e conversa com elas em minutos, varrendo hipóteses e casos extremos antes de gastar um real.
Alta empatia real e contexto profundo, mas com viés de seleção e envolvimento humano alto. O acesso ao usuário é o gargalo.
Acelera a descoberta e o envolvimento vira curatorial — mas a empatia é simulada (padrões) e exige auditoria dos dados.
Duas formas de validar uma ideia — e o que cada uma cobra de você.
Soa bom demais, e é aqui que a honestidade importa. A pesquisa acadêmica de 2025 e 2026 é clara: usuários sintéticos capturam tendências gerais, mas erram a magnitude dos efeitos e perdem a variabilidade bagunçada de gente de verdade. Pior: modelos treinados para agradar tendem à bajulação — devolvem feedback otimista demais e deixam de apontar a falha real. E eles alucinam.
Design tokens: quando design e código enfim leem a mesma fonte
A passagem do design para o código era a que mais doía — aquela do 16px que vira 17px. Os design tokens matam essa tradução. Uma cor deixa de ser “#2563EB no Figma e um hex ligeiramente diferente no CSS” e vira um token único que as duas pontas leem.
E agora isso tem um padrão. Em outubro de 2025, o Design Tokens Community Group publicou a primeira versão estável da especificação (2025.10) — um formato JSON neutro, sem dono, construído com Adobe, Google, Microsoft, Figma, Salesforce e dezenas de outros. (Vale a precisão: é um relatório de Community Group da W3C, não um W3C Standard formal.) Um token é só isto:
{ "color": { "brand": { "$value": "#2563EB", "$type": "color" }, "primary": { "$value": "{color.brand}", "$type": "color" } }}Desse mesmo arquivo, uma ferramenta como o Style Dictionary gera a variável do Figma e a classe do Tailwind. Design e código param de divergir porque param de ter duas fontes da verdade: passam a ter uma só, em JSON, que ambos consomem.
Open code: você é dono dos componentes — e por isso a IA pode reescrevê-los
A próxima passagem vazava na biblioteca de componentes. O modelo do NPM é uma caixa-preta: você instala um pacote, herda estilos que sobrescrever é um suplício e precisa aprender a API de outra pessoa. Quando algo não encaixa, você briga com a abstração.
O padrão que o shadcn/ui popularizou virou esse modelo do avesso — e ele próprio chama isso de Open Code. O código do componente não fica escondido num node_modules; ele aterrissa no seu repositório. Você não sobrescreve a abstração de um terceiro: você edita o seu próprio arquivo.
Instalação oculta, sobrescrita de estilos complexa e múltiplas APIs para aprender. Você briga com a abstração.
Esquema copy-paste completo, interface componível padrão e o código no seu repo — pronto para você (e uma IA) modificar.
A diferença entre consumir um componente e ser dono dele.
npx shadcn@latest add button# O código do componente cai no SEU repositório.# Você é dono, você edita — e um agente de IA também.E é aqui que 2026 fecha o argumento. O motivo mais forte para componentes em código aberto não é estética; é a IA. Um agente lê e reescreve código transparente muito melhor do que uma dependência opaca — e os registries do shadcn já são acessíveis a agentes via MCP. Componentes deixaram de ser pacotes imutáveis. O desenvolvedor é dono do topo da camada de código; o agente, também.
Fluido por padrão: a container query aposenta o breakpoint global
Sobra a passagem do layout. Por anos, o responsivo dependeu de breakpoints globais — “quando a tela tiver 768px, mude”. Mas o mesmo card vive numa sidebar estreita, num grid de três colunas e num modal, tudo na mesma largura de tela. O breakpoint global não sabe disso.
As container queries resolvem: o componente reage ao tamanho do contêiner-pai, não da janela. São Baseline desde 2023 (mais de 93% dos navegadores) e nativas no Tailwind v4. O card passa a se adaptar a quanto espaço ele tem ali, não a onde fica a borda da tela:
/* O card reage ao contêiner, não à viewport */.card-wrap { container-type: inline-size; }@container (min-width: 24rem) { .card { display: grid; grid-template-columns: 1fr 2fr; }}No Tailwind, é o mesmo com @container no pai e @sm:grid-cols-2 no filho. A pergunta mudou de “onde está a borda da tela?” para “quanto espaço eu tenho bem aqui?” — e é isso que torna um componente de fato portátil.
A estética da conversão
Com as fronteiras de construção caindo, a interface ficou livre para perseguir uma coisa só: conversão sem fricção visual. A hierarquia hoje é mobile-first e a narrativa acontece no scroll. Quatro movimentos dominam 2026: o dark mode nativo, com alternância fluida e estados ativos luminosos; a tipografia brutalista, de hierarquia extrema e tipos massivos; as micro-interações, respostas táteis e visuais sutis que guiam o usuário sem ele perceber; e a personalização por IA, que adapta conteúdo e layout em tempo real a partir de dados — algo tão simples quanto:
{ "geo": "BR", "content": "adaptable", "user_id": "88A12F" }O layout deixa de ser uma página fixa e vira uma resposta ao contexto de quem chega.
O loop de usabilidade com LLM — e a linha que o humano segura
Fechado o circuito de construção, falta a validação. E ela também ganhou um agente. A avaliação de interface agora usa a percepção visual do LLM para simular usuários antes de injetar código: um loop de captura de tela → um agente que “pensa em voz alta” e decide a próxima ação pela disposição visual → um segundo agente que localiza o elemento no HTML → uma automação que executa o clique e captura a próxima tela, repetindo até a tarefa terminar. É uma área de pesquisa real (UXAgent, Avenir-UX), e o pulo do gato dela é dar ao agente percepção visual de verdade, não só o DOM.
Mas o ponto mais importante é onde o agente falha. O LLM é um farejador de fricção visual microscópica: ele acha a seta de dropdown falsa, clica repetidamente nela, aponta o problema de acessibilidade que ninguém viu. E então erra o óbvio — não reconhece que a tarefa global foi concluída, não entende a lógica de negócio e, bajulador, suaviza problemas reais. O humano faz o contrário: trava no ícone de lápis ambíguo, mas entende o objetivo e contorna o erro.
O loop, e o trabalho que sobra para você
Junte as quatro forças e o ciclo de vida deixa de ser uma reta e vira um loop: ideação, onde personas sintéticas afiam hipóteses; sistematização, onde os design tokens em JSON carregam as regras visuais; implementação, onde o open code monta a interface; e validação, onde agentes LLM testam visualmente e retroalimentam o começo. Aprendizado contínuo, dados padronizados, interoperabilidade total.
Validam e afiam hipóteses rapidamente — o primeiro ciclo, antes do usuário real.
Traduzem regras visuais universais que design e código consomem da mesma fonte.
Componentes que você (e a IA) é dono montam a interface fluida.
Testam visualmente, farejam fricção e retroalimentam o ciclo.
Quatro estágios, um loop só — cada um lendo e escrevendo no mesmo substrato.
Repare no que sumiu: o bastão. Ele não cai mais porque não há mais bastão para passar — cada etapa lê e escreve no mesmo substrato legível por máquina, o JSON que costura pesquisa, design, código e validação. E o seu papel mudou de correr cada perna do revezamento para curar o loop: decidir o que entra, auditar o que a IA produz, segurar a linha do significado que a máquina não enxerga.
Há uma última dobra. O próximo usuário a consumir essas interfaces talvez não seja humano: à medida que agentes passam a navegar e agir por nós, o campo já fala em projetar para a experiência do agente, não só do usuário — de UX para AX. O loop que dissolveu o handoff entre as suas equipes é o mesmo que vai te conectar a quem nunca foi gente. Convém aprender a operá-lo agora.
Escrito em junho de 2026. As referências verificáveis — a primeira versão estável da especificação de Design Tokens (2025.10), o suporte a container queries (Baseline 2023) nativo no Tailwind v4, a filosofia Open Code do shadcn/ui e a pesquisa sobre usuários sintéticos e agentes de usabilidade — refletem o estado do ecossistema de produto nessa data. As comparações descrevem o comportamento de cada abordagem, não um benchmark único.
Arsenal do dev de elite.
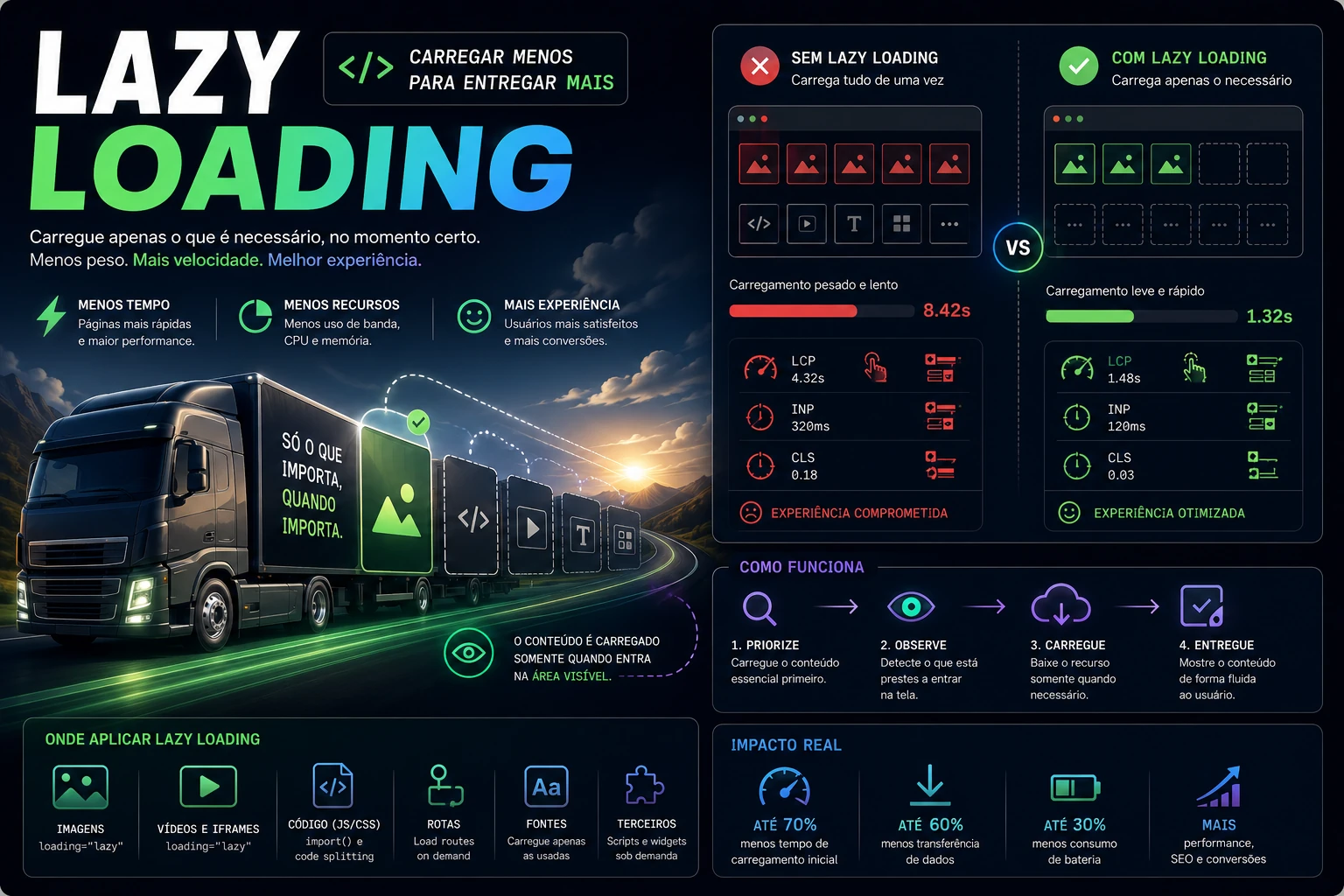
Lazy Loading: carregar menos para entregar mais
A web nunca foi tão rápida, e nunca engoliu tantos megabytes. A saída não é acelerar a entrega, mas adiar o que não importa agora.

Você está dimensionando elementos do jeito errado. E o CSS já tem a solução há anos.
Você define width: 200px. Funciona... até virar min-width, max-width e um calc() ilegível. E se o conteúdo dissesse o tamanho ideal?

TypeScript com Zustand + TanStack Query: os tipos que os tutoriais não mostram
Aprenda a lidar com os tipos que os tutoriais ignoram e use StateCreator, generics e factories para evitar erros.